AWS Data Lake And Amazon Athena Federated Queries

Supercharge your AWS data lake architecture with new query service extensions
AWS recently released an updated called federated queries for Athena. This new capability brings Athena closer in abilities to its relative, Facebook Presto. What is Presto? It is the foundational technology behind Athena!
Facebook describes Presto this way:
“Presto is an open-source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes. Presto allows querying data where it lives, including Hive, Cassandra, relational databases, or even proprietary data stores. A single Presto query can combine data from multiple sources, allowing for analytics across your entire organization.”
The ability to query multiple data sources is a welcome addition to Athena, providing new cost-effective paths to build a data lake efficiently. The new federated queries capability can open up new opportunities to extend your data lake architecture beyond the standard Amazon Simple Storage Service (S3) storage location or ELT/ETL.
So how can Athena help to manage data by reducing ETL costs? Federated queries!
What are federated queries?
Most organizations have data on a traditional data warehouse, data marts, or database using Oracle, Postgres, MySQL, and others. If you currently have a data lake using AWS Athena as the query engine and Amazon S3 for storage, having ready access to data resident in these other systems has value.
This is where the Athena federated query services open new pathways to query the data “in situ” with your current data lake implementation. The Athena federated query service allows running SQL queries across data stored in relational, non-relational, object, and custom data sources.

This has been a core component of Presto, so it is great to see AWS bringing the capability into the Athena feature set.
Who benefits from Athena federated queries?
Federated Queries enable business users, data scientists, and data analysts the ability to run queries across data stored in RDBMS, NoSQL, Data Lakes, and custom data sources. In a nutshell, a user can submit a SQL query that can get executed across multiple data sources in place. A query can connect to your S3 data lake, on-premise MySQL, or host Postgres on the cloud.
Federated queries afford business users new opportunities to analyze data in-place using analytics tools or business intelligence platforms that issue familiar SQL across supported data sources. They can also use scheduled SQL queries to extract and store results in Amazon S3 to enhance an existing data lake architecture.
How does Athena execute federated queries?
Athena federated queries are using AWS Lambda behind the scenes. AWS has open-sourced connectors for DynamoDB, HBase, DocumentDB, Redshift, CloudWatch Logs, CloudWatch Metrics, and MySQL, and PostgreSQL (or other JDBC-compliant relational data sources).
Connectors in Lambda are uses as the backbone to run federated SQL queries across data sources with Athena. AWS provides an SDK so engineers can build connectors to other data sources.
At the moment, existing Presto federated connectors are not supported for use in Athena federated queries. Given that the data connectors are publically available from Presto, they could get rewritten per the Athena SDK.
AWS Lambda, Athena and Federated Queries
As we mentioned previously, data source connectors for federated queries run on Lambda. For customers employing a serverless data lake architecture, Lambda provides the ability to minimize the need to manage infrastructure or scale for peak demands.
If you are familiar with Lambda, you are likely wondering about the 3 GB memory limit or the 15-minute runtime cap for Lambda. If you have a long-running query or modeling process, these Lamda limits can be a blocker for different data operations.
However, AWS has done some Lambda magic that makes use of multiple, or concurrent invocation, of functions that negate these limits. One caveat is that if data sources do not support parallel scans may encounter the Lamda runtime limits (15 minutes). Be mindful of this, especially if you are building custom connectors.
To pressure the Lambda connector approach, AWS rewrote the current S3 adaptor for Athena to run on Lambda. This rewrite allowed them to get 100 gigabits per second or 1.5 billion records per second.
Supported Source Systems
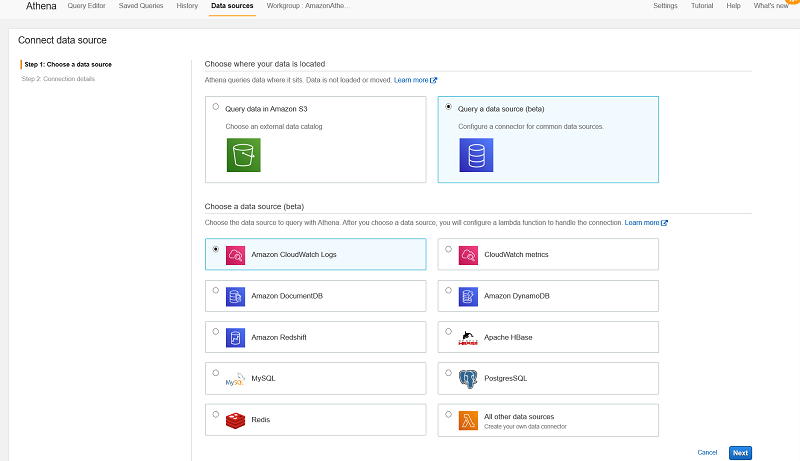
Here is the current list of AWS provided connectors:
- CMDB
- CloudWatch Logs
- CloudWatch Metrics
- Amazon DocumentDB
- Amazon DynamoDB
- Apache HBase
- JDBC to PostgreSQL, MySQL, Amazon Redshift
- Redis
- TPC-DS
For more information on data types related to federated queries, you can check out the docs here.
Lastly, while stored procedures are also not supported, you can use UDFs.
Conclusion
This release of federated queries continues the strategic direction building serverless data analytics stacks for your AWS data lake. Here are a few benefits the new federated queries offer teams;
- All query results are stored S3 bucket that you specify in your query. If your data lake architecture is focused on data ingest into S3, Athena’s query federation capabilities can help
- AWS, like Openbridge, has standardized on Apache Arrow as a standard data interchange format. This improves performance and optimizes cost.
- You can secure data lake resources such as the data catalog, tables, views, and other resources through IAM access controls
- Enhance or extend your data models with “in situ” data in a supported remote system. In these cases, traditional ETL can be minimized or eliminated
- Establish new data pipelines via these connectors to enhance your data management strategy and store outputs in Amazon S3.
- Connect to a supported datastore as “raw data” for use by Athena users. Take the raw “in situ” data and fuse it with structured and unstructured data in your lake
- Map data structures and data types in complex, muti data source environments
If you are looking to build a data lake with Amazon Athena, the Openbridge lake formation can get you up and running in a few minutes.
It has never been easier to get your data into Amazon Athena. Our service optimizes and automates the configuration, processing, and loading of data to AWS Athena, unlocking how users can return query results. With our new zero administration, AWS Athena service, you push data from supported data sources, and our service automatically loads it into your AWS Athena database!
DWant to discuss Amazon Athena for your organization? Need a platform and team of experts to kickstart your data and analytics efforts? We can help! Getting traction adopting new technologies, especially if it means your team is working in different and unfamiliar ways, can be a roadblock for success. This is especially true in a self-service only world. If you want to discuss a proof-of-concept, pilot, project, or any other effort, the Openbridge platform and team of data experts are ready to help.
Reach out to us at hello@openbridge.com. Prefer to talk to someone? Set up a call with our team of data experts.
Visit us at www.openbridge.com to learn how we are helping other companies with their data efforts.
References
- How is AWS Redshift Spectrum different than AWS Athena?
- AWS Athena — Code-free, Fully Automated With Zero Administration Data Pipelines
- 4 Steps To Create a Serverless Analytics Stack with Tableau and Amazon Athena
- Building A Serverless Business Intelligence Stack With Apache Parquet, Tableau, and Amazon Athena
- What is Presto, Facebook Presto Database, PrestoSQL or PrestoDB? A powerful SQL query engine
AWS Data Lake And Amazon Athena Federated Queries was originally published in Openbridge on Medium, where people are continuing the conversation by highlighting and responding to this story.
source https://blog.openbridge.com/aws-data-lake-and-amazon-athena-federated-queries-b7fc16fe3b2b?source=rss----4c5221789b3---4


